UX Design voor Machine Learning en ArtificiaI Intelligence
Vaak lijkt het erop dat wij mensen werken voor de computers. Terwijl dat natuurlijk omgekeerd zou moeten zijn. De vraag is: hoe kun je als designer nieuwe technologie inzetten om echt waarde toe te voegen voor je gebruikers? Zodat ze hun potentieel kunnen verwezenlijken?
Daarover ging de workshop User Experience Design for ML and AI van Josh Clark (@bigmediumjosh) bij Frozen Rockets Academy. En wat hij als eerste benadrukte is dat machine learning slechts een designmateriaal is, net als HTML of CSS.
Machine Learning als designmateriaal
Als je de beschikking krijgt over een nieuw designmateriaal begin je met het ontdekken van de mogelijkheden en beperkingen.
- Wat kan het?
- Hoe voelt het?
- Hoe kunnen we het gebruiken?
- En hoe verandert het ons?
Daar moeten we nu mee beginnen, want na het desktop- en het mobile-tijdperk bevinden we in de eerste fase van het Machine Learning-tijdperk.
Wat kun je nu met Machine Learning?
Met Machine Learning kunnen we patronen opsporen in data, en daar ‘iets’ mee doen. Josh deelt die mogelijkheden op in vijf categorieën:
- Aanbevelingen. Op basis van eerdere interesses kunnen we deze vergelijkbare zaken aanbevelen. Als jij bijvoorbeeld in de Slack van je organisatie zoekt op 'hiring process' zal Slack naast de zoekresultaten ook aanbevelingen tonen voor collega's en kanalen over gerelateerde onderwerpen.
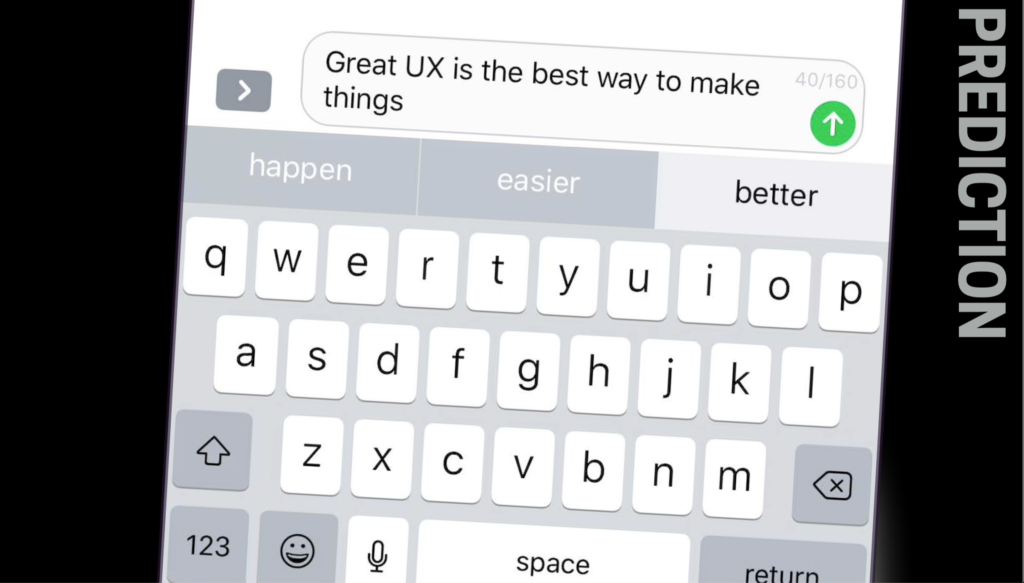
- Voorspellingen. Op basis wat je eerder deed verwachten we dat je nu dit wil doen. Een heel concreet voorbeeld zijn de QuickType-suggesties bovenaan je iPhone-toetsenbord (vanaf iOS 13 ook in het Nederlands!). Dit zijn zelflerende suggesties die zich continu aanpassen aan jouw woordgebruik.
- Classificaties. Met behulp van door mensen geclassificeerde datasets kan Machine Learning worden getraind om vergelijkbare patronen te herkennen en classificeren. Als je wel eens een enquete hebt gemaakt in Google Forms heb je misschien gezien dat daar real-time suggesties voor antwoordtypes worden gegeven op basis van de vraagstelling. Dit gebeurt op basis van de geclassificeerde keuzes van alle andere Google Forms-gebruikers.
- Clustering. Laat Machine Learning juist in ongeclassificeerde data de voor ons mensen onzichtbare patronen herkennen en groeperen.
- Generation. Machine learning zelf iets laten genereren, zoals een tekening, portretfoto of muziek.
Toegevoegde waarde van Machine Learning
Kortom, Machine Learning is gewoon heel goed in het uitvoeren van taken die:
- veel tijd kosten,
- zich steeds herhalen,
- aandacht voor detail vragen,
- foutgevoelig zijn, en
- ons geen werkplezier bieden.
Taken die we graag uitbesteden, waarmee Machine Learning eigenlijk het perfecte stuk gereedschap lijkt te zijn. Een voorbeeld daarvan is het ondersteunen van radiologen door het analyseren van grote hoeveelheden medisch beeldmateriaal. Als M.L. die taken overneemt komt krijgen we:
- betere antwoorden,
- nieuwe vragen om te onderzoeken,
- nieuwe data, en
- inzicht in onzichtbare patronen.
Daarmee creëren we voor onszelf de ruimte om te doen waar wij mensen goed in zijn: onze aandacht op een onderwerp richten en daarover een beslissing nemen.
Uiteindelijk draait het om de verhouding tussen mens en machine. En dat vraagt van UX designers dat zij Artificial Intelligence inzetten op problemen die het waard zijn om opgelost te worden. Want zoals Kranzberg’s First Law stelt:
Technology is neither good nor bad; nor is it neutral.
Aan de slag
 Na het bespreken van de huidige mogelijkheden en toegevoegde waarde van Machine Learning gingen we deze zelf uitproberen. Met speciaal ontworpen kaartsets werkten we ideeën uit in conceptuele prototypes.
Na het bespreken van de huidige mogelijkheden en toegevoegde waarde van Machine Learning gingen we deze zelf uitproberen. Met speciaal ontworpen kaartsets werkten we ideeën uit in conceptuele prototypes.
Vervolgens onderzochten we de betrouwbaarheid en vooringenomenheid (bias) van de ML image recognition-dienst van Microsoft Azure.
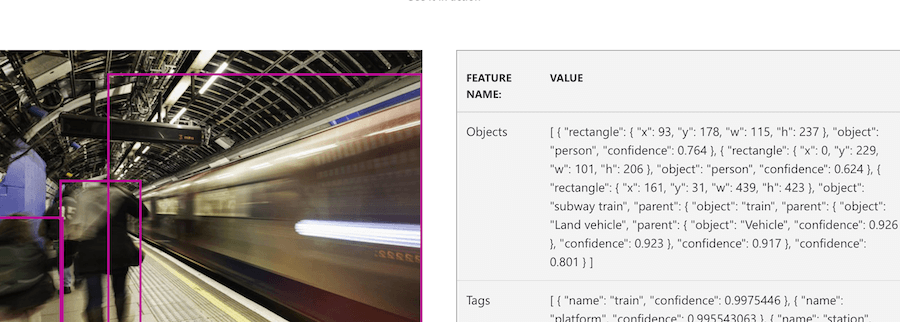
Daaruit leerden we al snel dat Machine Learning wordt getraind op ‘normaal’ tegenover afwijkend, en dat de onderliggende trainingsdata bepalend is voor de kwaliteit en betrouwbaarheid van herkenning en classificatie. Begin dus met te vragen:
- Welk probleem proberen we op te lossen?
- Welke data hebben we daarvoor nodig?
- Wie beschikt over die data?
(Side note: In 2015 maakte Google hun TensorFlow machine learning software open source. Dat konden ze doen omdat niet de software maar de data van strategisch belang is.)
Dit was deel 1 van mijn notities over UX Design voor Machine Learning en AI. Binnenkort deel 2!
Nieuwsgierig geworden?
Een compactere versie van zijn verhaal vertelde Josh Clark ook op btconf Berlin 2018. Aanrader!
AI Is The New Design Material - Josh Clark.